
Although podcasting is primarily audio, even before you get to the argument of whether video podcasts are really podcasts there are things that can be done to enhance the medium beyond just sound.
Chapters and Chapter art are something I'll come to another day, but this post looks at what transcription/subtitles can offer podcasting and comparing different ways of doing it.
The main advantages of providing a transcription are:
- Provide text for those who may have any hearing related issues
- Where the spoken language is not the listener's first language having text can help fill in any gaps
- Translate audio into text in a different language (that could also in itself then be turned to audio in that language)
- Create searchable archive of episodes
There are a huge range of options available for anyone who wants to transcribe and/or add subtitles to their work, these vary in simplicity, accuracy and cost.
Over the 15 or so services I've tested although no system will be 100% perfect what I've found is that all services/tools I tested were pretty close and only required minor tweaks and that this is only going to get better as technology progresses, this was evident to me as different services made different errors but between them would have got almost everything correct so I don't think it'll be long before the various approaches/tools get combined into something even smarter than we have now.
This doesn't mean you can get away with no human effort as using machine only you can end up with something like this BBC Doctor Who video where the captions auto generated by YouTube are not 100% compared to the provided subtitles - what you see may depend on your default settings, for example watching the video on Desktop I got the BBC subtitles, on mobile I had no subtitles then when I requested captions it defaulted to the auto-transcribe rather than supplied subtitles.
I think for any podcast with any reasonable aim of professionalism just leaving it to the machine and not giving any subtitles/transcription a once over isn't an option or you end up with something like the below.


The above brings up another issue of any AI in that it will reflect what its been trained on (I'd imagine it'd have no issue correctly spelling Phoebe for example), but that's for another day.
To do this, I had the help of a few fellow podcasters (Vic, Ian and Brian) who, using the asynchronous features of ZipMessage talked briefly about themselves to give me a sample file that I have then put through a number of transcription services and will be comparing over the next few posts.
These services range from web based options like Otter.ai, in-podcasting services such as Snipd and tools such as Google Cloud and AssemblyAI which may be a bit less user-friendly but offer more potential for large scale transcription.
This first post in the series looks at a tool which is free (sort of), easy to use and a lot of people may already have access to: Microsoft Word.
The catch for using Word is that it requires the online version at Office.com which allows 5 hours of transcription per month.

The transcribe option you can see above is not available in the desktop version, just online, from the image below you can see the interface you get, the process correctly identified that there were 4 different speakers and gives you the option to change speaker 1, speaker 2 etc., to the correct names

In terms of accuracy it was pretty good (once I've gone through all the transcription tools I'll provide a more thorough comparison at the end) with the errors (off a 3 minute composition) shown below:
| Transcription | Should Have Been |
| Hello | Hi There |
| world Podcast | world of podcasts |
| In stitch | then stitch |
| in any other links | and any other links |
| looked extend | look to extend |
| Mike Media | MIC Media |
| Mict | MIC |
| FY | FYI |
| On | one |
| Running | Run (the um after run caused the issue) |
| AFRO | AVRO |
| Brian Castle | Brian Casel |
| Galland | Gal |
As with the issue mentioned earlier with Ncuti, names and acronyms are areas that usually prove most problematic. Vic runs a company called MIC Media so sounds the same as Mike. Brian gets called Ryan in some of the transcription services.
The other issue that will impact both humans and AI is clarity and speed of speech. I'm a bit of a mumbler and words often run into each other where Ian speech is slower and clearer as you'd expect from an experienced podcaster and as such fewer errors in the transcription.
Word allows the option to add speaker details and timestamps to the main text and edit as you would any normal work document add images etc., so particularly useful as something like an internal company document. The biggest downside is the inability to save as an SRT file for use in subtitles but for short files at least that isn't a huge manual overhead to fix.
Also, being Word you can translate the resulting file (after you've corrected any issues) into a different language in a matter of seconds.
OtterAI
OtterAI at time of starting this project looking at Transcription services was my go-to tool, primarily as it enables you to include an interactive version of your podcast on your website.
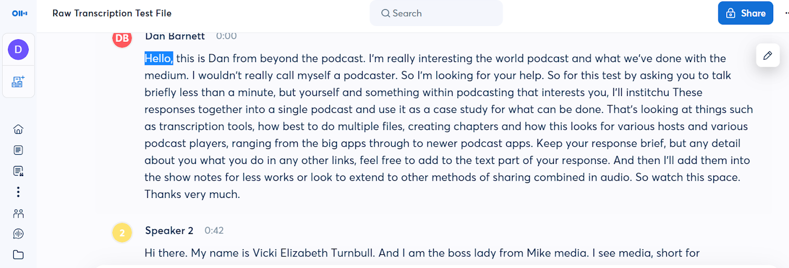
| Transcription | Should Have Been |
| Hello | Hi There |
| interesting | interested in |
| world podcast | world of podcasts |
| what we've done with the medium | what can be done with the medium |
| but yourself | about yourself |
| institchu | then stitch these |
| for less works or look | If all this works I'll look |
| Vicki | Vic |
| Mike | MIC |
| I see media | MIC Media |
| good acts | good eggs |
| calm | called |
| afro | AVRO |
| conversation | conversations |
| allow | allowed |
| Brian Castle | Brian Casel |
One of the advantages OtterAI has over some more basic tools is the ability to output a SRT file, also you can embed the transcription as an interactive player as shown below:
The biggest downside is probably the recent price hike to $16.99 per month (but 'only' half that per month if you commit to annual subscription). $100 is not a major amount but not negligible either, OtterAI presumably hoping the rise in annual pays better than the drop off in monthly they are bound to have as a result.
One interesting thing when comparing OtterAI's transcription with what was really said is that is was arguably worse than Microsoft Word for the first 3 (UK based) speakers but better for Brian who is American. Whether that's chance or based on Otter AI's training data I don't know.
In the next post I'll look at some of the other specialist transcription services such as Poddin and Podcastle.
Also, I'll discuss OpenAI as one of the tools but this article by Benjamin Bellamy of Castopod is worth a read on what that can offer.
